
Amazon Kinesis Data FirehoseでLambda Processorを使わずにレコード間に改行コードを自動挿入するアイデア(AWS CDK)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX 事業本部 IoT 事業部の若槻です。
Amazon Kinesis Data Firehoseを利用する際には、Delivery stream に Put した JSON 形式のデータがAmazon Athenaでクエリ可能なJSON Lines形式で出力されるように、次のいずれかの対応を取ることが多いかと思います。
- レコードの Put 時にデータ末尾に改行コードを付与する(クライアント側の対処)
- Lambda Processor を使用してレコード間に改行コードを自動挿入する(Delivery stream 側の対処)
しかし前者の対応だとクライアント側で対処が難しい場合もあります。また後者の対応は Processor 用の Lambda 関数を実装する必要があり IaC 含めた実装コストが掛かります。
今回は、Amazon Kinesis Data Firehose でレコード間に改行コードを自動挿入するための、上記2つとは異なる第3の方法を AWS CDK のテンプレートとともにご紹介します。
2024/02/25 追記
本記事よりもシンプルな方法で同じ実装が可能であることが分かりましたので、以下記事で紹介しているのでそちらを参照ください。
つきましては本記事の内容は参考程度に留めておいてください。
方法
Amazon Kinesis Data Firehose では、S3 Bucket に出力されるデータの namespace(プレフィックス)として、レコード毎に指定のキー値を使用したプレフィクスを付与できるDynamic Partitioningという機能が利用できます。
この Dynamic Partitioning では付随する機能としてレコード間に任意の区切り記号を自動挿入でき、これを改行コードの挿入に利用できないか?というのが今回のアイデアです。
この区切り文字自動挿入の機能は単独利用はできない(詳細後述)のですが、フォルダ(プレフィクス)に対する Dynamic Partitioning が不要なケースでも対応できるように、次の 2 つの観点で方法を確認してみました。
- フォルダ(プレフィクス)に対する Dynamic Partitioning を利用する場合
- フォルダ(プレフィクス)に対する Dynamic Partitioning が不要な場合
フォルダ(プレフィクス)に対するDynamic Partitioningを利用する場合
Dynamic Partitioning の機能を利用したい場合は、前回の以下エントリで紹介した方法がそのまま利用できます。
これにより例えばareaキーに対する Dynamic Partitioning を設定した Delivery stream に対して次のような JSON 形式のレコードを個別に Put した場合。
{"id":"u001","count":3,"area":"Shinjuku"}
{"id":"u001","count":1,"area":"Akihabara"}
{"id":"u002","count":5,"area":"Ikebukuro"}
{"id":"u002","count":2,"area":"Akihabara"}
{"id":"u003","count":4,"area":"Shinjuku"}
出力先の S3 Bucket にはdata/${area}というフォルダ(プレフィクス)でパーティション値毎にオブジェクトが格納され、その内容はレコードが改行区切りとなった JSON Lines となっています。
{"id":"u001","count":1,"area":"Akihabara"}
{"id":"u002","count":2,"area":"Akihabara"}
{"id":"u002","count":5,"area":"Ikebukuro"}
{"id":"u001","count":3,"area":"Shinjuku"}
{"id":"u003","count":4,"area":"Shinjuku"}
Dynamic Partitioning を利用する場合はこれで良さそうですね。
フォルダ(プレフィクス)に対するDynamic Partitioningが不要な場合
一方でフォルダ(プレフィクス)に対する Dynamic Partitioning が不要な場合。もしかするとこちらのケースの方が多いかも知れません。
その場合は Dynamic Partitioning で次のような実装を行います。
import { Construct } from 'constructs';
import {
aws_s3,
aws_athena,
aws_kinesisfirehose,
Stack,
StackProps,
RemovalPolicy,
Duration,
Size,
} from 'aws-cdk-lib';
import * as glue_alpha from '@aws-cdk/aws-glue-alpha';
import * as firehose_alpha from '@aws-cdk/aws-kinesisfirehose-alpha';
import * as firehose_destinations_alpha from '@aws-cdk/aws-kinesisfirehose-destinations-alpha';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// データソース格納バケット
const dataBucket = new aws_s3.Bucket(this, 'dataBucket', {
bucketName: `data-${this.account}-${this.region}`,
removalPolicy: RemovalPolicy.DESTROY,
});
// Athenaクエリ結果格納バケット
const athenaQueryResultBucket = new aws_s3.Bucket(
this,
'athenaQueryResultBucket',
{
bucketName: `athena-query-result-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
}
);
// データカタログ
const dataCatalog = new glue_alpha.Database(this, 'dataCatalog', {
databaseName: 'data_catalog',
});
// データカタログテーブル
new glue_alpha.Table(this, 'dataCatalogTable', {
tableName: 'data_catalog_table',
database: dataCatalog,
bucket: dataBucket,
s3Prefix: 'data/',
dataFormat: glue_alpha.DataFormat.JSON,
columns: [
{
name: 'id',
type: glue_alpha.Schema.STRING,
},
{
name: 'count',
type: glue_alpha.Schema.INTEGER,
},
{
name: 'area',
type: glue_alpha.Schema.STRING,
},
],
});
// Athenaワークグループ
new aws_athena.CfnWorkGroup(this, 'athenaWorkGroup', {
name: 'athenaWorkGroup',
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`,
},
},
recursiveDeleteOption: true,
});
// Kinesis Firehose Delivery Stream
const deliveryStream = new firehose_alpha.DeliveryStream(
this,
'deliveryStream',
{
deliveryStreamName: 'deliveryStream',
destinations: [
new firehose_destinations_alpha.S3Bucket(dataBucket, {
dataOutputPrefix: 'data/!{partitionKeyFromQuery:key1}', //末尾"/"を省略するとオブジェクト名先頭にキー値が付加される
errorOutputPrefix: 'error/!{firehose:error-output-type}/',
bufferingInterval: Duration.seconds(60),
bufferingSize: Size.mebibytes(64),
}),
],
}
);
// Delivery StreamのDynamic Partitioning設定
const cfnDeliveryStream = deliveryStream.node
.defaultChild as aws_kinesisfirehose.CfnDeliveryStream;
cfnDeliveryStream.addPropertyOverride(
'ExtendedS3DestinationConfiguration.DynamicPartitioningConfiguration',
{
Enabled: true,
}
);
cfnDeliveryStream.addPropertyOverride(
'ExtendedS3DestinationConfiguration.ProcessingConfiguration',
{
Enabled: true,
Processors: [
{
Type: 'MetadataExtraction',
Parameters: [
{
ParameterName: 'MetadataExtractionQuery', //パーティションキーをレコードから抽出するクエリ
ParameterValue:
'{key1: {dummy: ("-")} | .dummy}', //全てのレコードでキー値として"-"を返す
},
{
ParameterName: 'JsonParsingEngine',
ParameterValue: 'JQ-1.6', //クエリエンジンにjqを使用
},
],
},
{
Type: 'AppendDelimiterToRecord', //レコード間の区切り記号の挿入
Parameters: [
{
ParameterName: 'Delimiter',
ParameterValue: '\\n', //改行コードを挿入
},
],
},
],
}
);
}
}
Dynamic Partitioning を利用する場合とのパラメータ上の変更点が主に 2 箇所あります。
- 83 行目の
dataOutputPrefixの指定で、data/!{partitionKeyFromQuery:key1}として末尾の/を省略することにより、パーティションキーの値がオブジェクト名の先頭に付与されるようになります。これにより出力されたデータをクエリする側(Glue,Athena)でパーティションの余計な考慮は必要なくなります。 - 前述の指定によりパーティションキーがフォルダ名に使用されなくなるため、パーティションキーの値は正直何でもよくなります。よって、112 行目では全てのレコードで固定のキー値として
-を返すように{key1: {dummyKey: ("-")} | .dummyVal}という指定をしています。
#レコードの内容によらず、固定のキー値"-"が返る
$ echo '{"key": "val"}' | jq '{dummyKey: ("-")} | .dummyKey'
"-"
上記を CDK Deploy したら動作確認をしてみます。
Delivery stream に対して下記のデータを連続で Put します。
aws firehose put-record \
--delivery-stream-name deliveryStream \
--cli-binary-format raw-in-base64-out \
--record '{"Data":"{\"id\":\"u001\",\"count\":3,\"area\":\"Shinjuku\"}"}'
aws firehose put-record \
--delivery-stream-name deliveryStream \
--cli-binary-format raw-in-base64-out \
--record '{"Data":"{\"id\":\"u001\",\"count\":1,\"area\":\"Akihabara\"}"}'
aws firehose put-record \
--delivery-stream-name deliveryStream \
--cli-binary-format raw-in-base64-out \
--record '{"Data":"{\"id\":\"u002\",\"count\":5,\"area\":\"Ikebukuro\"}"}'
aws firehose put-record \
--delivery-stream-name deliveryStream \
--cli-binary-format raw-in-base64-out \
--record '{"Data":"{\"id\":\"u002\",\"count\":2,\"area\":\"Akihabara\"}"}'
aws firehose put-record \
--delivery-stream-name deliveryStream \
--cli-binary-format raw-in-base64-out \
--record '{"Data":"{\"id\":\"u003\",\"count\":4,\"area\":\"Shinjuku\"}"}'
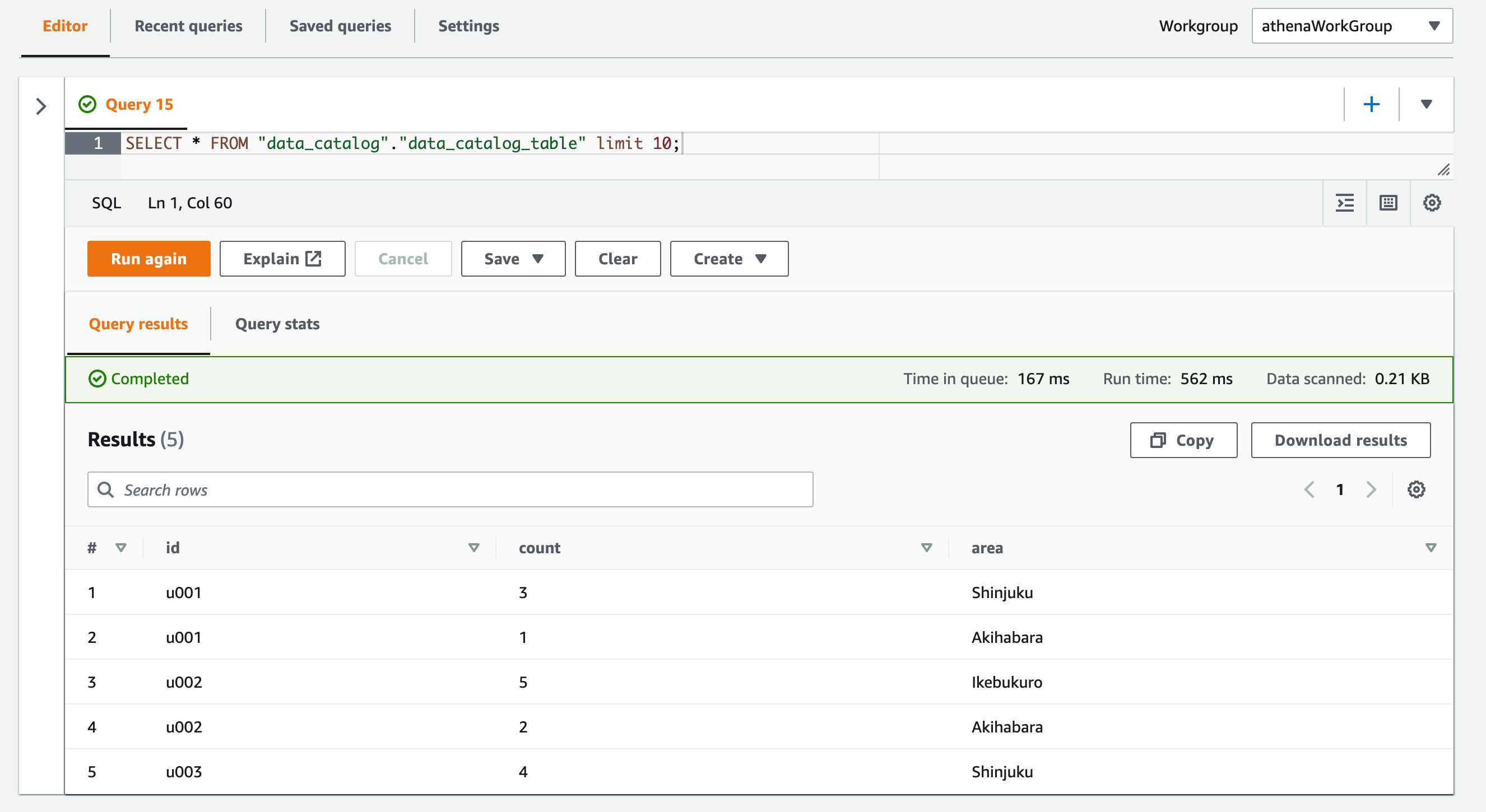
出力先 Bucket の内容を確認すると、プレフィクスとしてオブジェクト名先頭に-が付与されたオブジェクトが出力されています。
$ aws s3 ls s3://${BUCKET_NAME} --recursive
2022-08-07 19:26:37 212 data/-deliveryStream-11-2022-08-07-10-24-12-03105d79-867c-3a5f-aa33-ba46de8d7e59
オブジェクトをダウンロードして開くと、ちゃんと改行コード区切りの JSON Lines 形式になっています!
{"id":"u001","count":3,"area":"Shinjuku"}
{"id":"u001","count":1,"area":"Akihabara"}
{"id":"u002","count":5,"area":"Ikebukuro"}
{"id":"u002","count":2,"area":"Akihabara"}
{"id":"u003","count":4,"area":"Shinjuku"}
よって Athena からのクエリでもちゃんと全レコードを取得することができました!
SELECT * FROM "data_catalog"."data_catalog_table" limit 10;
注意点
Dynamic Partitioning設定時はプレフィクスにキーを必ず含める必要がある
わざわざオブジェクト名先頭にキー値を含めなくて良さそうな気もしますね。
// Kinesis Firehose Delivery Stream
const deliveryStream = new firehose_alpha.DeliveryStream(
this,
'deliveryStream',
{
deliveryStreamName: 'deliveryStream',
destinations: [
new firehose_destinations_alpha.S3Bucket(dataBucket, {
//dataOutputPrefix: 'data/!{partitionKeyFromQuery:key1}',
dataOutputPrefix: 'data/',
errorOutputPrefix: 'error/!{firehose:error-output-type}/',
bufferingInterval: Duration.seconds(60),
bufferingSize: Size.mebibytes(64),
}),
],
}
);
しかし上記のようにして CDK Deploy するとS3 Prefix should contain Dynamic Partitioning namespaces when Dynamic Partitioning is
enabledというエラーとなります。
$ cdk deploy ProcessStack ✨ Synthesis time: 3.68s ProcessStack: deploying... [0%] start: Publishing c7a2755120b90491b73493d8f5689b26ec8850f7caf2c600ef1fa9820ebaf012:current_account-ap-northeast-1 [100%] success: Published c7a2755120b90491b73493d8f5689b26ec8850f7caf2c600ef1fa9820ebaf012:current_account-ap-northeast-1 ProcessStack: creating CloudFormation changeset... 7:41:00 PM | UPDATE_FAILED | AWS::KinesisFirehose::DeliveryStream | deliveryStream7D22820B Resource handler returned message: "S3 Prefix should contain Dynamic Partitioning namespaces when Dynamic Partitioning is enabled (Service: Firehose, Status Code: 400, Request ID: fd98c6f6-2298-1621-a6f1-5e0d7f19b8f2, Extended Request ID: 9gAL7 J9nP0LWtmQ6VJEFGDs9W3gdJZcGAxnCKTgW5XCcpqwpGC7Vwnel9trA+o7o1hjeMzYZQZM35OYaKk4w64Oe8IFfk6Qf)" (RequestToken: fef60b0d-d1b2 -4f9a-fba3-02eaff8c923f, HandlerErrorCode: InvalidRequest)
Dynamic Partitioning 設定時はプレフィクスにキーを必ず含める必要があるようです。
レコード間の区切り記号の自動挿入のみを利用することはできない
では Processor としてMetadataExtractionの設定を行わず、AppendDelimiterToRecordのみ追加した場合はどうでしょうか。
cfnDeliveryStream.addPropertyOverride(
'ExtendedS3DestinationConfiguration.ProcessingConfiguration',
{
Enabled: true,
Processors: [
/*
{
Type: 'MetadataExtraction',
Parameters: [
{
ParameterName: 'MetadataExtractionQuery', //パーティションキーをレコードから抽出するクエリ
ParameterValue:
'{key1: {dummy: ("-")} | .dummy}', //全てのレコードでキー値として"-"を返す
},
{
ParameterName: 'JsonParsingEngine',
ParameterValue: 'JQ-1.6', //クエリエンジンにjqを使用
},
],
},
*/
{
Type: 'AppendDelimiterToRecord', //レコード間の区切り記号の挿入
Parameters: [
{
ParameterName: 'Delimiter',
ParameterValue: '\\n', //改行コードを挿入
},
],
},
],
}
);
この場合は CDK Deploy するとMetadataExtraction processor should be present when S3 Prefix has partitionKeyFromQuer
y namespace.というエラーとなります。
$ cdk deploy ProcessStack ✨ Synthesis time: 2.84s ProcessStack: deploying... [0%] start: Publishing 7ce817b4e584f994374681cb3fc93f5555d6d0a7c58a6d0c20974b4c86059c04:current_account-ap-northeast-1 [100%] success: Published 7ce817b4e584f994374681cb3fc93f5555d6d0a7c58a6d0c20974b4c86059c04:current_account-ap-northeast-1 ProcessStack: creating CloudFormation changeset... 7:49:06 PM | UPDATE_FAILED | AWS::KinesisFirehose::DeliveryStream | deliveryStream7D22820B Resource handler returned message: "MetadataExtraction processor should be present when S3 Prefix has partitionKeyFromQuer y namespace. (Service: Firehose, Status Code: 400, Request ID: e418df94-d1d9-933d-bf71-45758e2828a3, Extended Request ID: HlviRU2SQiWhsJWrKhaOtMC2j5PKEqIukkH4rvwqvqD/css/i5JUiuLuoQGPqR3n13eLP6nL4Hhq94uoym8W4jEx8/VsdID3)" (RequestToken: 187ecd39 -2d51-faa2-6736-a92d37e60a45, HandlerErrorCode: InvalidRequest)
レコード間の区切り記号の自動挿入のみを利用することはできないようです。
Dynamic Partitioningのキー値は空文字とすることはできない。
今回プレフィクスに使用する値としてハイフン-を指定しましたが、'{key1: {dummy: ("")} | .dummy}'というクエリで空文字を返すのは出来ないのでしょうか。
cfnDeliveryStream.addPropertyOverride(
'ExtendedS3DestinationConfiguration.ProcessingConfiguration',
{
Enabled: true,
Processors: [
{
Type: 'MetadataExtraction',
Parameters: [
{
ParameterName: 'MetadataExtractionQuery', //パーティションキーをレコードから抽出するクエリ
ParameterValue:
//'{key1: {dummy: ("-")} | .dummy}',
'{key1: {dummy: ("")} | .dummy}',
},
{
ParameterName: 'JsonParsingEngine',
ParameterValue: 'JQ-1.6', //クエリエンジンにjqを使用
},
],
},
{
Type: 'AppendDelimiterToRecord', //レコード間の区切り記号の挿入
Parameters: [
{
ParameterName: 'Delimiter',
ParameterValue: '\\n', //改行コードを挿入
},
],
},
],
}
);
上記の実装とした場合は、Put したレコードが次のようなpartitionKeys values must not be null or emptyというエラーとなり正常に配信されなくなります。
{
"attemptsMade": 1,
"arrivalTimestamp": 1659819856785,
"errorCode": "DynamicPartitioning.MetadataExtractionFailed",
"errorMessage": "partitionKeys values must not be null or empty",
"attemptEndingTimestamp": 1659819922676,
"rawData": "eyJpZCI6InUwMDEiLCJjb3VudCI6MywiYXJlYSI6IlNoaW5qdWt1In0="
}
パーティションキーの値は必ず空文字以外の文字列とする必要があるようです。
オブジェクト名の先頭が"_"だとAthenaのクエリ対象とならない
空文字がだめならと当初アンダースコア_をパーティションキーの値にしようとしました。Put したデータの配信までは問題なく行われました。
$ aws s3 ls s3://${BUCKET_NAME} --recursive
2022-08-07 19:26:37 212 data/_deliveryStream-11-2022-08-07-10-24-12-03105d79-867c-3a5f-aa33-ba46de8d7e59
後は Athena でクエリするだけで良さそでしたが、上記オブジェクトに記載されたレコードを SELECT クエリで取得できませんでした。どうやらオブジェクト名の先頭が_だと Athena のクエリ対象とならないようです。
そこで今回は代わりにハイフン-を使う実装としました。
おわりに
Amazon Kinesis Data Firehose で Lambda Processor を使わずにレコード間に改行コードを自動挿入するアイデアのご紹介でした。
もしかしたら正攻法ではないかも知れませんが実装コストは下がりそうです。今後のアップデートでレコード間の区切り記号の挿入機能だけを単独で使えるアップデートがあれば嬉しいですね。
参考
以上








